
Balancing Elegance and Operations in ETL
Imagine the perfect data warehouse for your business. It probably consists of a set of elegant Stars or even Neutron Stars for each of your critical business entities organized into a relatively simple snowflake. It would be easy to manage, all of your calculations would be in one place. There’d be a single point of access which would make governance and change management easy. From a software engineering perspective, we never risk the duplication of code. Unfortunately, this architecture introduces a fair bit of risk that’s frequently unanticipated.
Let’s compare this design to an alternative strategy of purpose-oriented datamarts. You can see the differences between the two architectures below:
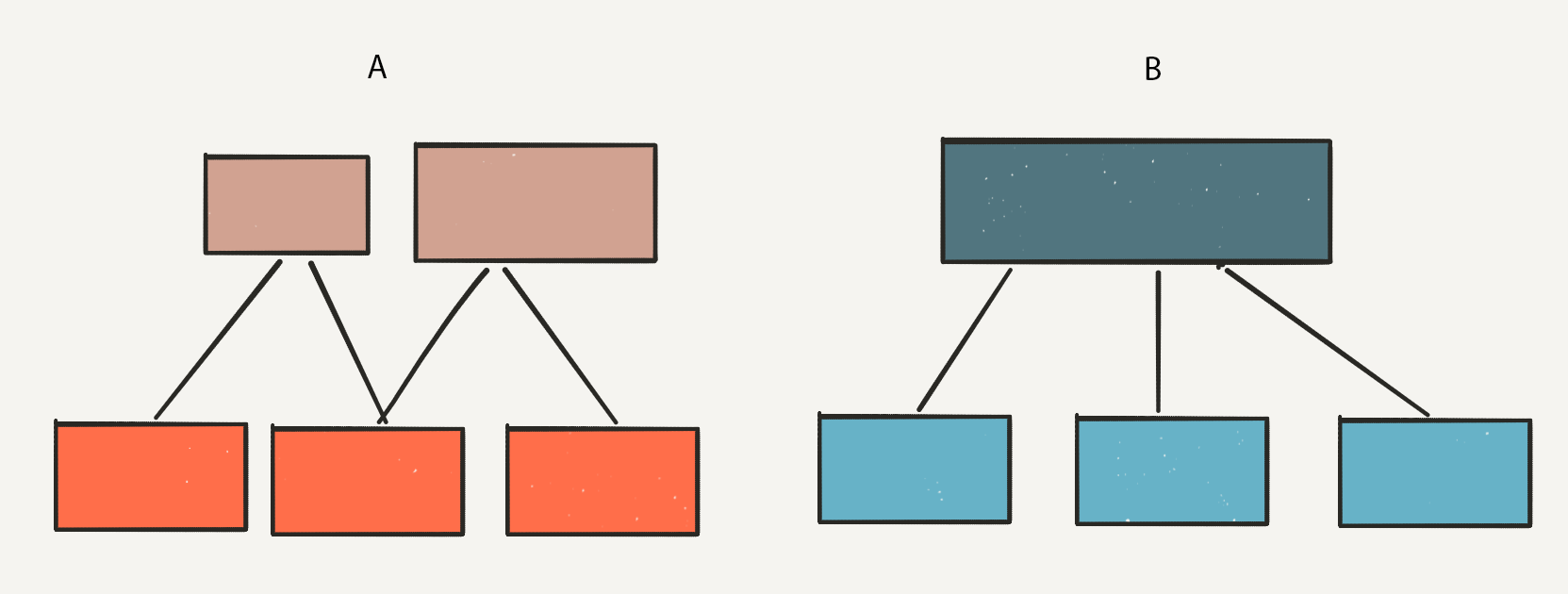
In Strategy A, we produce smaller, much more focused datasets. There’s a fair bit of redundancy between them, which is undesirable. Just how undesirable depends on your technology infrastructure and governance requirements, but let's take the extreme example of a pure GUI or SQL-driven ETL framework and extreme governance requirements. In this case, we cannot share logic between individual pathways. At best, we’ll copy & paste between each data mart when a revision to the business logic is needed, at worst we’ll lift and shift logic between pathways in some way. These strategies increase the risk of errors, and we probably miss a pathway or make some other mistake in the process. In a best-case scenario, our code is procedural/functional instead of declarative. We also might have the benefit of shared libraries, shared DAG nodes and unit tests. All of these strategies dramatically reduce the maintenance burden and risk. Complexity increases, but we’ve mitigated it a fair amount at the cost of somewhat higher setup and initial development costs.
However, the bigger question is, why do we want to do this in the first place. What is the benefit of ditching the monolithic data warehouse? Perhaps the most substantial benefit of creating discrete data warehouses is the reduced size of each warehouse. Reduced size won’t make a significant impact on query times if you store the underlying data in a columnar format but, it reduces computation overhead and can hopefully improve delivery times. It also frees us to prioritize specific workflows in the event of scarcity. Legal compliance reporting, operations, and customer needs trump accounting, data science, and other analytics workloads. Increased parallelization of the datamart builds an option; provided our infrastructure can support it. We also gain the ability to manage scope a fair bit. After all, it’s easier to deliver a small, well-defined set of features for a small number of users. These smaller data marts load into high-performance reporting databases downstream easily as well.
So, which strategy is right for you? It depends on your organizational culture more than anything. Creating separate data marts can be ideal for firms that have the engineering maturity to manage the diverse code paths and enforce consistent data definitions. If you don’t have the maturity to manage the complexity, you’re looking at the high risk of swampiness using this strategy, and you need to tread carefully.